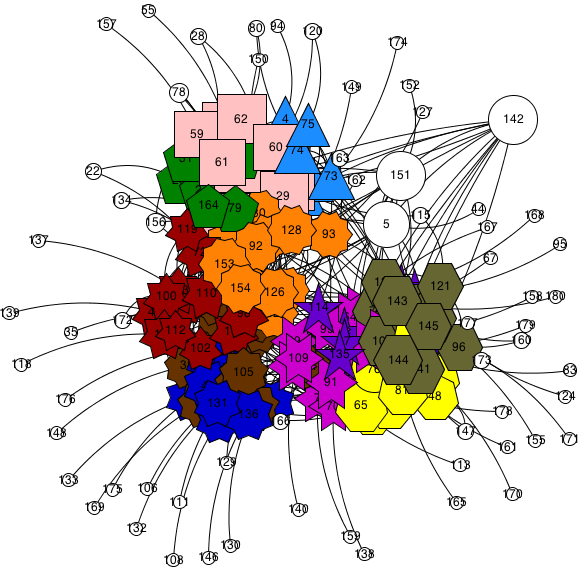
TopLeaders
TopLeaders is a community mining method inspired by k-means, which extracts desired number of communities (given as input) from a network/graph. Communities are groups of highly inter-related nodes that have relatively less relations to other nodes outside their group (a.k.a clusters). TopLeades community mining algorithm assumes that each community consists of a leader and its followers. It detects different leaders and their followers based on relationships between nodes. Moreover, it determines the outlier nodes that belong to no community and the hub nodes that are bridging between different communities.
Related Publications
- Reihaneh Rabbany K. and Osmar R. Zaiane, A Diffusion of Innovation-Based Closeness Measure for Network Associations, the COMMPER Workshop on Mining Communities and People Recommenders, in conjunction with the IEEE International Conference on Data Mining (ICDM), Vancouver, Canada, December 2011
- Reihaneh Rabbany K., Jiyang Chen, Osmar R. Zaiane, Top leaders Community Detection Approach in Information Networks, 4th SNA-KDD Workshop on Social Network Mining and Analysis, in conjunction with the ACM SIGKDD conference on Knowledge Discovery and Data Mining (KDD), Washington, DC, July 25 2010
Download
Getting Started
- Download the jar file
- Download the sample network karate.pairs
- Open a terminal in Mac or Linux
- Change your directory to where you saved those files
- In the terminal type
- The result (detected communities) is saved in the same directory named "karate.pairs.clusters" while you see the progress of the algorithm in the terminal as:
- These are optional parameters that you could set for the algorithm ("-help")
Running Global with [ k:2, o: 0.0, c: 16.0, h: 0.0 ]
Initial leaders: [1, 33]
Iteration: 1, leaders: [1, 34]
Iteration: 2, leaders: [1, 34]
Partitioned to: Number of Clusters: 2 , size: 17.0 +/- 1.0 in [16.0,18.0] , number of Hubs: 0 , Outliers: 0
[ Communities(2): [[1, 2, 3, 4, 5, 6, 7, 8, 11, 12, 13, 14, 17, 18, 20, 22], [34, 32, 33, 9, 10, 15, 16, 19, 21, 23, 25, 24, 27, 26, 29, 28, 31, 30]]
Hubs: []
Outliers: []]
-o: how much outliers should be detected, (real number, default 0, numbers in between 0 and 1 are treated as percents for automatic scaling according to networks' charactresitics, negative numbers: ignored and program would predict the proper threshold)
-h: how much hubs should be detected (real number, default 0, numbers in between 0 and 1 are treated as percents for automatic scaling according to networks' charactresitics, negative numbers: ignored program would predict the proper threshold)
-c: how much centers could be close together (0..1, would be automatically set by the program if no value is provided)
-out: outputfilename (default $input.clusters)
Coverage
Visualized Examples
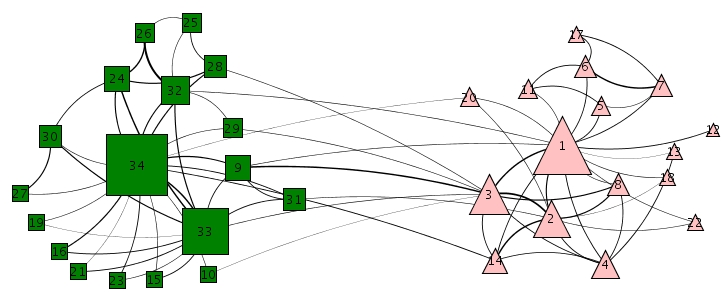
WKarate Club (weighted) by Zachary (input, groundtruth):
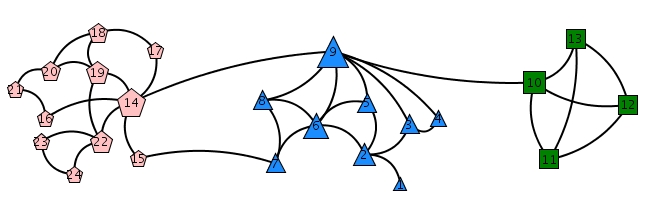
Sawmill Strike data sets (input, groundtruth):
NCAA Football Bowl Subdivision (input, groundtruth):